- Einleitung
- Möglichkeiten der SLI-Zusammenarbeit
- Zum Chip: Diskussionswürdiges
- Methoden: Anti-Aliasing im Detail
- Methoden: T-Buffer - der Alleskönner
- Methoden: Full scene Anti-Aliasing / Motion Blur
- Methoden: Depth of Field
- Methoden: Vereinfachung
- Methoden: FXT1 - Texturen mit perfektem Detailreichtum:
- Methoden: Vertexbasierendes anisotropisches Filtering
Einleitung
Dieser Artikel dient dazu einen Techniküberblick über den VSA-100-Chip ("Voodoo Scalable Architecture") von 3dfx, der Verwendung in den Grafikkarten Voodoo4 4500, Voodoo5 5500 und Voodoo5 6000 fand, zu liefern.
Man sollte vorerst die reinen Rohdaten des Chips betrachten:
Auffällig ist, dass eine T-Buffer-Nutzung mit nur einem Chip nicht möglich ist, es werden mindestens zwei VSA-100 benötigt um den T-Buffer zu nutzen.
Hier kommt auch gleich die Besonderheit des VSA-100-Chips zum Tragen, er ist nämlich multichipfähig, es können bis zu 32 VSA-100-Chips zusammenarbeiten (bei bestimmten Workstationkarten anzutreffen).
Auch ist ein Punkt sehr unklar: "AGP-Features, sind sie vorhanden, oder nicht?". Der VSA-100 unterstützt keine exekutiven AGP-Modi (also kein AGP-Texturing), da dies jedoch keine signifikanten Vorteile in Anwendung bringt ist dem auch nicht nachzutrauern.
Es ist die Rede von bis zu 32 MB Hochgeschwindigkeit SDRAM pro VSA-100-Chip, warum kein DDR SDRAM? Zu der Zeit als der VSA-100 entworfen wurde, war DDR SDRAM noch wesentlich teurer als SDRAM und so sah man keinen direkten Anlass ihn dahingegen auf DDR SDRAM auch zu spezifizieren. Es sollte jedoch eine später Version (der VSA-101) auch mit DDR SDRAM zusammenarbeiten können.
Nun zu der Besonderheit des SLI (Scan Line Interleaving). Das SLI hat primär nichts mit einem Zusammenarbeiten von mehreren GPUs (Graphic Processing Units) an ein und der selben Tätigkeit zu tun. Vielmehr bedeutet es, dass zwei (oder mehr) GPUs sich die Arbeit dahingegen logisch aufteilen (also nicht beide an "einem" Prozess arbeiten), wobei die geraden und ungeraden Linien gezeichnet werden (wie bei der Voodoo²) oder eben ganze Bänder - bestehend aus sog. Scan-Lines - zusammengefasst werden (Voodoo5).
Die beiden Methoden haben alle eines gemeinsam: Sie arbeiten niemals in oder auf dem selben Pixel.
SLI arbeitet durch die Partitionierung des Bildschirms in "Scan-Line-Bändern" - es teilt den Bildschirm dabei nicht in Hälften auf (so wie die "SLI-Variante" von Metabyte) -. Durch den Einflusses des T-Buffers muss jeder VSA-100-Chip mit 2 Subsamples arbeiten: Also mit einer 2 Chip-Variante ergibt dies ein Total von 4 Subsamples, nur dies aktiviert die vollen T-Buffer-Funktionen und natürlich auch genauso die 4xRG-FSAA (es ist zwar auch möglich bei nur total 2 Subsamples die T-Buffer-Funktionen zu aktivieren, jedoch ist deren sichtbares Ergebnis dann sehr gering). Wenn wir nun bei der 2-Chip-Variante (Voodoo5 5500) im "T-Buffer-Modus" sind - also mit 4 Subsamples minimal arbeiten - so handelt es sich nicht mehr um SLI im eigentlichen Sinne (laut Methode #3 beim Vorhandensein von nur 2 VSA-100). Der Nutzer hat also die Wahl: Entweder SLI und damit eine hohe Gesamtperformance oder aber T-Buffer & 4xRG-FSAA und damit eine niedrigere Gesamtperformance aber dafür eine deutlich höher Bildqualität. Die 4-Chip-Variante (Voodoo5 6000), wie schon bereits oben kurz erwähnt, beherrscht den simultanen Einsatz von SLI und "T-Buffer-Modus".
Jedes "Chip-Paar" kreiert ja seinen eigenen 4 Subsample-T-Buffer und fügt dann, je nach dem zugewiesenen "Scan-Line-Band", die Subsamples zusammen (laut Methode #3 beim Vorhandensein von 4 VSA-100). Auch hier kann natürlich wieder zugunsten von Geschwindigkeit ein 4-faches SLI erzwungen (anstatt nur 2-faches). Auch die Methode #4 mit 8xRG-FSAA kann mit dem T-Buffer-Effekten genutzt werden. Hierzu gelten dann jedoch auch wieder die selben Bedingungen, wie für die 2-Chip-Variante (also kein SLI möglich).
Auffällig ist, dass eine T-Buffernutzung mit nur einem VSA-100-Chip nicht möglich ist, es werden mindestens zwei VSA-100 benötigt, um den T-Buffer zu nutzen.
Hier kommt auch gleich die Besonderheit des VSA-100-Chips zum tragen, er ist nämlich MultiChipfähig, es können bis zu 32 VSA-100-Chips zusammenarbeiten (und sie tun es bei bestimmten Workstationkarten auch).
Auch ist ein Punkt sehr unklar: "AGP-Features, sind sie vorhanden oder nicht?".
Der VSA-100 unterstützt keine exekutiven AGP-Modi (also kein AGP-Texturing), da dies jedoch keine signifikanten Vorteile in Anwendung bringt, ist dem auch nicht nachzutrauern.
Es ist die Rede von bis zu 32 MB Hochgeschwindigkeit SDRAM pro VSA-100-Chip, warum kein DDR SDRAM? Zu der Zeit als der VSA-100 entworfen wurde war DDR SDRAM noch wesentlich teurer als SDRAM und so sah man keinen direkten Anlass ihn dahingegen auf DDR auch zu spezifizieren. Es sollte jedoch eine später Version (der VSA-101) auch mit DDR SDRAM zusammenarbeiten können. Das Interessante dabei ist natürlich die Speicherung der Texturen. So müssen gewisse Texturen doppelt vorhanden sein (jeder Chip verfügt ja bekanntlich über maximal 32 MB Grafikkartenspeicher, der determiniert ist, also nicht getauscht wird untereinander), es handelt sich dabei um die Texturen, die in den entsprechenden "Scan-Line-Band" liegen - also kann, je nach geschickter Wahl dieser "Textur-mehr-Aufwand" gesteuert/vermindert werden -. Der Frame-Buffer und der Subsample-Buffer ist dabei jeweils komprimiert vorliegend in jedem 32 MB-Paar des zugehörigen Chips, so wird kein unnötiger Platz verschwendet beim kreieren der Subsamples und einzelnen Frames.
Die Textur-Management-Units (TMUs) sind zweifach vorhanden, jede von ihnen verfügt über 2 Pipelines, beim verwenden von Single-Texturing pro Pixel-Modus, erreicht man hiermit eine vollwertige 2 Pixel pro Takt Füllrate. Wenn hingegen im Dual-Texturing pro Pixel-Modus wird nur noch eine effektive Füllrate von einem Single Pixel pro Takt erreicht. Dies bedeutet, dass die Single-Textur Füllrate für einen einzelnen VSA-100-Chip doppelt so hoch ist wie für der eine Voodoo3, auf der selben Frequenz getaktet, die Dual-Texturing Füllrate entspricht annähernd dem der Voodoo3 hierbei. Durch einige Änderungen in der Microarchitektur werden jedoch ca 20% mehr Leistung von dem VSA-100-Chip im Multi-Texturing geboten als im Vergleich zu einem gleichgetakteten Voodoo3-Chip.
Warum gibt es nun keine 3-Chip-Varianten bzw. kein 6xRG-FSAA?
Auch hier ist die Beantwortung wieder einmal simpel: Eine 3-Chip-Variante wurde von dem Hersteller (3dfx) ausgeschlossen, da ansonsten mathematische Probleme auftreten würden bei der Adressierung von Berechnungen unter bestimmten Umständen, so wäre eine neue Lösung zum Erstellen der 4 Subsamples benötigt worden, was dem Mehraufwand in der Entwicklung sicherlich nicht förderlich gewesen wäre. Der 6xRG-FSAA-Modus hat dabei ein ähnliches Problem mit den Subsamples, man hätte ein VSA-100-Model benötigt, welches mindestens 3 Pixel pro Takt berechnen kann (und nicht nur 2 wie im originalen VSA-100), also fiel dies weg für den VSA-100-Chip.
Der VSA-100-Chip beherrscht definitiv 2xRG-FSAA und je nach Anzahl der Chips verdoppelt sich auch die Anzahl der Samples. Anti-Aliasing hat erst einmal im Prinzip etwas mit dem Rendering auf Subpixel-Ebene zu tun: Die Zahl 2x, 4x oder 8x bedeutet schlechthin, dass die 2-, 4- oder 8-fache Anzahl von Pixeln gerendert werden, jeweils die Hälfte davon auf horizontaler und die andere Hälfte auf vertikaler Subpixel-Achse (also 1:1, 2:2 oder 4:4).
Dadurch wird ein Pixel doppelt, vierfach bzw. achtfach so genau auf Subpixelebene abgetastet als dies normal geschehen würde. Das interessante dabei ist, dass die Subpixel um 45° gedreht werden, so werden aus 4 Subpixeln 8 Abtastungen, dies entspricht dann einer Genauigkeit von 8 Subsamples, obwohl eigentlich nur 4 verwendet wurden. Beim 8xRG-FSAA werden sogar stolzen 16 Abtastungen (also je 2 pro Subpixel) erreicht.
Ein VSA-100-Chip kann bis auf 2 Subsamples (Im folgenden zur Vereinfachung Modus-0 genannt) genau auf einen Pixel rendern. Die Füllrate sinkt dabei von der ursprünglichen 2 Pixel pro Takt Leistung (wenn kein RG-FSAA aktiviert ist) auf den 1 Pixel pro Takt Leistung im Modus-0. Aus einem Pixel werden folglich 2 Subpixel abgeleitet, diese werden um 45° gedreht. So wird einmal der X- und der Y-Wert abgetastet und durch das Drehen entsteht noch ein weiterer, versetzter X'- und Y'-Wert (mit ' bezeichnet, um den Unterschied zu verdeutlichen, es handelt sich nicht um den selben Wert!), der ebenfalls abgetastet wird. Die Subsamples werden dann im Framebuffer zusammengefügt und auf den Bildschirm ausgegeben. Der Modus-0 wird für alle anderen Anti-Aliasing-Methoden vorausgesetzt, so entsteht dann das 4xRG-FSAA oder gar das 8xRG-FSAA, je nach VSA-100-Anzahl (der genaue Arbeitsvorgang ist unter den verschiedenen SLI-Modi bereits weiter oben zusammengefasst).

Der T-Buffer wurde von 3dfx dafür konzipiert, um Spielen einen neuen Grad an Realismus zu geben, er stellt neben dem Anti-Aliasing und den Shadern die wichtigste Erneuerung in der Grafikkartenindustrie dar, es soll Photorealismus dargestellt werden.
Der Unterschied zwischen einer in Echtzeit gerenderten Szene und einer "vorberechneten" Szene ist auch heut noch deutlich sichtbar. Bisher wurde auf normalen Konsumer-PCs keine derartigen photorealistischen Effekte ermöglicht, der T-Buffer sollte dies ändern. Unterstützt werden dabei:
Das FSAA eliminiert "Bildungenauigkeiten", um es salopp auszudrücken, ganz spezifisch sind hier die auffallenden Schrägen von schiefen Objekten gemeint, die eine Art Treppe bilden, sie werden auch als "spatiale Artefakte" bezeichnet. Das Spatial-Anti-Aliasing "glättet" diese Artefakte nun und verhindert so den Treppeneffekt (wie genau dies abläuft steht bereits im Abschnitt: "Anti-Aliasing im Detail"). Aber es gibt noch ein weiteres Bildartefakte, neben dem "Treppeneffekt", dem sog. "funkeln" (engl. scintillating) oder "plötzliches auftreten" (engl. popping) von Polygonen. Mit "funkeln" ist hierbei schlicht das Problem gemeint, wenn ein dünnes, schmales Polygonobjekt in ferner Distanz anfängt zu flimmern, also die Polygone abwechselnd entweder dargestellt oder weggelassen werden, oftmals fehlt dann eine Verbindungslinie in der Bewegung oder ähnliches. Ursache hierfür ist eine zu geringe Auflösung des Samples (engl. under-sampling), wobei die Genauigkeit auf Sample-Ebene einfach nicht ausreichend ist eine - ja eigentlich unendliche - 3D-Umgebung darzustellen. Dies gehört ebenfalls in den Bereich der spatialen Artefakte. Eine weitere "Unterkategorie" des FSAA ist das temporäre Anti-Aliasing, dies wird genutzt, um MB zu erzielen und desweiteren noch das fokussierende Anti-Aliasing, um das DoF darzustellen. Beim Anti-Aliasing sollte man unbedingt zwischen dem Fullscene- und dem Edge-Anti-Aliasing unterscheiden, beim letzteren werden nämlich bloß die Außenkanten der Polygone geglättet und nicht das generelle Problem des "under-samplings", dem "scintillating", behoben und ergibt dann daher auch im Endeffekt eine niederwertige Bildqualität.
Das temporäre Aliasing, ist ein weiteres Manko in der Bildqualität, es sorgt für einen statischen Eindruck von Objekten, da alle Ecken die gleiche Tiefenschärfe aufweisen. Die Anomalie beruht jedoch nicht nur auf ein "under-sampling" sondern viel eher die Bewegung des Objektes ist die Ursache, da jene nicht mit einer genügend hohen Frequenz abgetastet und dargestellt wird und so die Sample-Rate zu gering ist. Als Ergebnis sieht man eine bildhafte (sprunghafte) Bewegung des Objektes von einem Frame zum nächsten, anstatt eine fließende (filmähnliche) Bewegung. Um diesem entgegenzuwirken erhöht man einfach die Anzahl der Bewegungsphasen des Objektes und bringt diese in die selbe Frame hinein, dies ist jedoch absolut unökonomisch und viel zu Leistungsintensiv für normale Grafikkarten. Im T-Buffer wird der selbe Effekt viel leistungsschonender erzielt, indem einfach mehrere getrennte Bewegungsdaten zusammengefasst werden. Also spielen wieder die Subsamples eine große Rolle, so können 2, 4 oder 8 dieser Subsamples zusammengefasst werden - anders als beim Anti-Aliasing ist hier jedoch nicht die mehrfache Abtastung in X oder Y-Richtung wichtig sondern viel eher die Gesamtanzahl der Samples im Verlauf der Bewegung. Dies äußert sich dann durch den MB bei den sich bewegenden Objekten als sichtbaren Effekt auf dem Bildschirm. Anstatt eine zusammengefasste Bewegung pro Frame zu sehen, entstehen mehrere Bewegungs-Samples zu einer Bewegung. Dies erklärt auch, warum der 2xT-Buffer eigentlich ungeeignet ist für MB, da so nur 2 Bewegungs-Samples sichtbar wären und dies für einen glaubwürdigen Effekt nicht ausreicht, sondern wenigstens 4 Bewegungs-Samples nötig sind, um auch optisch attraktiv zu sein. Das Ganze verleiht dem Bild dann mehr Realismus und nimmt die sonst übliche "Statik" der Computerszenen.

Ähnlich verhält es sich mit dem DoF, er erzeugt Tiefenunschärfe und fokussiert bestimmte Objekte. Der Vorgang funktioniert ähnlich wie beim MB, die Subsamples spielen auch hier wieder die bedeutendste Rolle beim Kreieren des Effektes. Jedoch nicht wie beim Anti-Aliasing oder beim MB sondern viel mehr als Teilbilder für fokussierende Objekte. So wird beispielsweise eine Vase im Hintergrund fokussiert (scharf dargestellt) und die Umgebung als unscharf aufgefasst, dies wird dann in einem Bildausschnitt festgehalten (in sogenannten Fokus-Smaples) und immer so weiterberechnet - also nur den fokussierten Teilausschnitt als Weiterberechnung - anstatt das gesamte Bild weiter zu berechnen.

Die Kombination von MB und DoF wird genutzt, um sanfte Schatten (auch Halbschatten) und Reflexionsunschärfe darzustellen. Bisher wird der Stencil-Buffer, verwendet um Schatten von Objekten zu kreieren, dabei entstehen unnatürlich scharfe Kanten beim Schattenumriss. Unter Verwendung des T-Buffers können Halbschatten dargestellt werden. Bei der Reflexionsunschärfe handelt es sich um ein Phänomen aus der Natur, wo zum Beispiel poliertes Holz nur matt reflektiert, welches abhängig von der Nähe des Betrachters zum Reflexionsobjekt war, dieser Effekt war bisher nicht realisierbar.

Allgemein kann man die verwendete Technik auch als Multi-Sampling bezeichnen. Die Arbeitsweise des T-Buffers ist bei all diesen Effekten wie folgt:
Die Stufe mit dem rendern von multiplen Bildern, wird dabei sooft wiederholt, wie die verwendeten Anzahl der Subsamples vorgeben, also 2, 4 oder 8 mal. Im Gegensatz zum Akkumulation-Buffer wird keine Stufe benötigt, wo der Akkumulation-Buffer zurück zum Back-Buffer geschrieben wird und dies spart Zeit und Ressourcen. Ein weiterer Vorteil gegenüber dem Akkumulation-Buffer ist, dass man die Effekte MB und DoF nun partikular einsetzen kann und nicht auf das ganze Bild angewendet werden müssen, da ja mehrere Schreibvorgänge im Back-Buffer vorgenommen werden.
In jedem 3D-Spiel werden Texturen verwendet, womit die "nackten" Polygone beklebt werden, um ihnen eine Struktur zu verleihen. Die Größe dieser Texturen schwankt dabei stark, je nach gewünschtem Effekt und Detailgrad wird sie größer. Der VSA-100 unterstützt eine Texturgröße mit bis zu 2048x2048 Pixeln in 32-bit. Einen Einsatz von solch gigantischen Texturen ist jedoch nicht möglich ohne ein bandbreitenschonendes Texturkompressionsverfahren zu benutzen, da ansonsten die Texturen von dieser Größe bis zu 16 MB Speicher belegen würde und somit nicht mehr viel Platz für andere Texturen bzw. wichtigeren Geometriedaten sein würde. Eine Lösung ist hierbei das FXT1 von 3dfx, es handelt sich um eine neue Form des Kompressionsverfahren, welches die Größe der Textur vermindert, so dass effektiv mehr genutzt werden können. Es ergibt sich dabei folgendes Verhältnis von Texturgrößen und Farbtiefen:
Beim FXT1 handelt es sich um ein 4-bit Texturkompressionsverfahren, wobei 4-bit pro Texel komprimiert werden. Das Kompressionsverfahren wird auch als "Encoding" bezeichnet. Beim FXT1 wird das Bild in mehrere 4x4 und / oder 4x8 Texel-Blöcke zerlegt (je nachdem, welches Verhältnis günstiger ist), dabei kommen vier verschiedene Algorithmen zum tragen, die je nach Bedarf und auch visueller Qualität genutzt werden:
Dies ist der komplexeste Abschnitt in diesem Artikel, zum einen, da es sich um ein Feature handelt, welches von den regulären 3dfx-Treiber nicht angeboten wird und zum anderen, weil es sich allgemein auch um eine schwierige Materie handelt. Deshalb erst einmal allgemein etwas zum Anistropischen Filtering sagen, bevor auf die Details der Nutzung durch den T-Buffer eingegangen wird.
Ein gängiges Verfahren, um Textur-Aliasing zu vermeiden ist das Mipmapping, dabei wird sehr oft eine Unschärfe zumeist in einer bestimmten Richtung als Nebeneffekt geschaffen, um das Aliasing in der entgegen gesetzten Richtung zu vermeiden. Ein anisotropisches Texturing würde diese unerwünschte Unschärfe durch ein Filtern in verschiedenen Richtungen unter unterschiedlichen Winkeln unterbinden, jedoch auf Kosten der Geschwindigkeit.
Das Texturemapping ist ein szenenkomplexitäts-erhöhender Multiplikator, wobei ein komplexes Bild in ein simpelstrukturiertes Bild aufgeschrieben wird, um die Szene komplexer zu gestalten. Das Mipmapping beinhaltet dabei einen distanz- und winkelvariierenden isotropischen "low-pass" Filter, wobei man davon ausgehen kann, dass die MIP-Filter-Größe von dem Winkel und der Distanz der betrachteten Textur abhängig ist, dennoch aber gleichmäßig über alle Richtungen der Textur geht (also in X- und Y-Richtung). Das korrekte Rendern von gestreckten Texturen oder betrachteten Texturen unter einen Winkel erfordert ein anisotropisches Filtern.

Ein MIP-map besteht dabei aus einer pyramidialen vorgefilterten und "downgesampelten" (verkleinerten) Texturen, wobei jeder MIP-map-level dabei der um die Hälfte verkürzten Größe (in beiden Richtungen) des vorigen MIP-map-levels entspricht. Die TMU bestimmt nun einen Skalierungsfaktor der einzelnen Fragmente und wählt das nächst passende aus, also die zwei Mip-map-level, welche sich um den passenden Faktor unterscheiden. Die Hardware benutzt nun 1, 2, 4 oder 8 der acht umgebenden Texels, um den Farbwert des Fragmentes zu rekonstruieren. Während das Mipmapping einwandfrei auf Texturen anwendbar ist auf die direkt gesehen wird, so versagt diese Methode bei abweichenden Winkeln indem eine Unschärfe in eine Richtung produziert wird, um den Detailgrad in der anderen Richtung zu wahren. Die beste Methode ist es einen elliptischen Gauss'schen Filter zu benutzen, wobei eine Ellipse die Projektion eines zirkularen Gauss'schen Pixels mit dem sichtbaren Platz (Bildschirmplatz) und dem Texturplatz annähernd filtert. Es gibt zwei Möglichkeiten den elliptischen Filter zu konstruieren, zum einem mit rohen Texeln oder mit dem Kombinieren von unterschiedlichen MIP-map-samples mit dem Filterfußabdruck (daher auch der Name: "footprint assembly" => FA). Wobei die FA-basierenden Algorithmen mit relativ wenig MIP-map-samples auskommen und so ressourcenschonend arbeiten.
Das FA hat als Grundlage einen zirkularen Gaussfilter-Kernel, der ein Bildschirmfragment abdeckt. Wenn eine Oberfläche unter einem bestimmten Winkel eingesehen wird, so wird die Projektion dieses Kernels auf den Texturplatz angenähert durch einen elliptischen Gaussfilter durch die Summe von Texture-Samples.

In 2a sieht man den zirkularen Umriss, der symbolisiert, wie das Standard MIP arbeitet, durch zu große Samples außerhalb des "Fußabdruckes" (der Ellipse) würde dies zur Unschärfe der Textur führen. In 2b sieht man den idealen Verlauf durch die Textur-Samples als konzentrische Kreise. Der Hauptunterschied zwischen den einzelnen FA-Methoden besteht in der Anordnung und Platzierung der Textur-Samples. In der vollen Hardwareanpassung wird natürlich versucht so dicht wie möglich an der eigentlichen Ellipsenform zu bleiben (siehe in 2d). Das vertexbasierende anisotropische Texturing berechnet die Textur-Samples durch Vertexe (Scheitelpunkte), die Textur-Sample-Größe ist durch die Stufe des MIP-map-levels bestimmt.

Eine normal gezeichnete Textur gibt ein großes MIP Textur-Samples, zentriert auf jedem Fragment über die Geometrie (siehe 3a). Die Stufe des MIP-levels skaliert die Größe des Textur-Samples mit der Größe des Standard Mipmapping, welches ausgewählt wurde. Mit der Stufe des MIP bekommen wir kleinere Textur-Samples pro Fragment (siehe 3b), um nun ein Textur-Sample zu platzieren innerhalb des Texturareals - umgeben von den Fragmenten -, wird die Texturkoordinate jedes Vertexes um einen kleinen Betrag in die benötigte Richtung geändert (siehe 3c und 3d). Die Textur-Samples sind mit dem vermischen ("blending") von purer Vertexberechnung oder "per-pass Alpha" belastet, nur die Vertexberechnung wird hierbei im weiteren beachtet, diese birgt nun wieder 2 neue Fehlerquellen in sich:
Weil die Stufen der Anisotropie auf dem Polygon variieren können ist man auf eine einzige mögliche Anzahl der Textur-Samples und eine Stufe des MIP-levels beschränkt. Um nun auch dem Ausnahmezustand (aus Abbildung 2a) gerecht zu werden, wurde die Anzahl der Textur-Samples und Stufen der MIP-levels auf Objekt-Ebene und nicht auf Polygon-Ebene angewendet.

Wenn der Wechsel der Anisotropie auf einem Polygon nicht einheitlich geschieht bekommt man Aussetzer ("Offsets") in der Mitte des Polygons (siehe 4a und 4b). Die Höhe der Textur-Samples und der Textur-Aussetzer muss pro Durchlauf äquivalent auf dem Polygon sein. Um nun beide Fehler der Vertexberechnung zu eliminieren wird eine abweichende Sampling-Startegie genutzt: Der gesamte Fußabdruck wird abgetastet anstatt nur die platzierten Textur-Samples entlang der Hauptrichtung der Anisotropie (siehe 4c bis 4f). Dies erlaubt nun eine adäquate Rekonstruktion mit einer hohen Variabilität der zirkularem bis zu hoch exzentrischen Filterschärfe mit stets der selben Anzahl an Textur-Samples und Koordinaten. Um die Textur-Samples nun zusammenzufügen wird eine Transformation aus dem zirkularem Gauss'schen Filter und dem elliptischen Filter gemacht, die Position des Textur-Samples wird also von zirkularer zur elliptischen Ebene transformiert, um ein adäquates Überlappen der Samples zu garantieren, wird die Distanz der MIP-Stufen zueinander in Betracht gezogen (nur die angrenzenden Stufen). Dies lässt einen Freiheitsgrad im Algorithmus zu, der sich folgendermaßen äußert: Die Textur-Sample kann entweder vom kanonischen zirkularem Gebiet oder vom zirkularem zum elliptischen Gebiet transformiert werden.
Eine Möglichkeit der Transformation entlang der Hauptachse der Ellipse mit der X-Achse (Abszisse) im zirkularem Gebiet und von der Nebenachse (siehe 4a) mit der Y-Achse (Ordinate). Diese Möglichkeit ist gleich mit der Achsenberechnung des klassischen FA (im Gegensatz zum vertexbasiertem FA) aber ist ungeeignet für das nah-zirkulare vertexbasierte FA, die Auswahl, welche Achse länger ist ändert sich rapide und nicht vorhersehbar. Die Transformation vom Bildschirm zur Textur mit dem elliptischen Filter liefert ein stabileres Koordinatensystem (siehe 4c) aber es erfordert eine engere Abtastung, um Richtungsartefakte zu vermeiden (siehe 4d). Das System die Bildschirmkoordinaten zu erstellen ist dabei dasselbe, um auch Supersampling in Software darzustellen. So können wir nun ein stabileres Koordinatensystem erstellen, welches auch die Richtungen der Anisotropie erkennt, ohne dabei von der Haupt- und Nebenachse zu unterscheiden. Unsere finale Selektion für die Abtastung des Musters nutzt eine schwankende Anordnung (siehe 4f), dies vermeidet eine Verdoppelung, welches im Zentrum der entlanggegangen Achse auftritt. Es wird außerdem ein angenähertes Koordinatensystem, welches leichter für die Berechnungen ist und auch die Interpolationen unter den Polygonen berücksichtigt.

Nun zum Realisieren auf VSA-100-Chips. Im Prinzip ist alles sehr einfach, man adressiert nur die 3dfx_multisample anstatt wie bisher die GL_EXT_texture_lod_bias oder die GL_SGIX_texture_lod_bias OpenGL-Extensionen. Das interessante dabei ist, dass die selben Subsamples wie für das RG-FSAA genutzt werden auch für diesen spezifischen Prozess verwendet werden können, also bis zu 16-faches Anisotropisches Filtering kombiniert mit 2xRG-FSAA ohne jeglichen Geschwindigkeitsverlust. Dabei werden 8 Textur-Samples genutzt und diese sind 2 mal abgetastet (für das FSAA) durch den "Jitter-Prozess", wobei die Subsamples-Anzahl der Jitter-Samples-Anzahl entspricht (also 8x2) und ohne merklichen Verlust an Leistung in diesem Modus. Für das 4xRG-FSAA ergibt sich dann 8x4, weil 4 Subsamples "gejittert" werden und ein effektives anisotropisches Filtering von 32 tap - auch hier ebenfalls ohne Leistungsverlust. Sobald der T-Buffer also genutzt werden kann steht auch automatisch die anisotropische Filterung zur Verfügung (als gl_anisotropic).
Man sollte vorerst die reinen Rohdaten des Chips betrachten:
- 16 bis 32MB Hochgeschwindigkeit SDRAM Speicher pro VSA-100-Chip
- 350 MHz RAMDAC
- 333 bis 367 Megapixels/s
- Echtzeit Hardware Anti-Aliasing (2 Subsamples pro Pixel) RG-FSAA (rotated grid Full-scene Anti-Aliasing)
- FXT1 und DirectX Texturkompression
- 8-bit palettisierte Texturen
- 32-Bit Rendering
- 32-Bit Texturen
- 24-Bit Floating Point Depth Buffer (Z oder W)
- 8-Bit Stencil Buffer
- K x 2K Texturen
- PCI oder 4x AGP mit Full Sideband Support
- DirectX, OpenGL, und Glide als unterstützte APIs
- DVD-Hardwareassistent integriert
- 0,25 Mikron Fertigungstechnik mit 6 Schichten)
Auffällig ist, dass eine T-Buffer-Nutzung mit nur einem Chip nicht möglich ist, es werden mindestens zwei VSA-100 benötigt um den T-Buffer zu nutzen.
Hier kommt auch gleich die Besonderheit des VSA-100-Chips zum Tragen, er ist nämlich multichipfähig, es können bis zu 32 VSA-100-Chips zusammenarbeiten (bei bestimmten Workstationkarten anzutreffen).
Auch ist ein Punkt sehr unklar: "AGP-Features, sind sie vorhanden, oder nicht?". Der VSA-100 unterstützt keine exekutiven AGP-Modi (also kein AGP-Texturing), da dies jedoch keine signifikanten Vorteile in Anwendung bringt ist dem auch nicht nachzutrauern.
Es ist die Rede von bis zu 32 MB Hochgeschwindigkeit SDRAM pro VSA-100-Chip, warum kein DDR SDRAM? Zu der Zeit als der VSA-100 entworfen wurde, war DDR SDRAM noch wesentlich teurer als SDRAM und so sah man keinen direkten Anlass ihn dahingegen auf DDR SDRAM auch zu spezifizieren. Es sollte jedoch eine später Version (der VSA-101) auch mit DDR SDRAM zusammenarbeiten können.
Nun zu der Besonderheit des SLI (Scan Line Interleaving). Das SLI hat primär nichts mit einem Zusammenarbeiten von mehreren GPUs (Graphic Processing Units) an ein und der selben Tätigkeit zu tun. Vielmehr bedeutet es, dass zwei (oder mehr) GPUs sich die Arbeit dahingegen logisch aufteilen (also nicht beide an "einem" Prozess arbeiten), wobei die geraden und ungeraden Linien gezeichnet werden (wie bei der Voodoo²) oder eben ganze Bänder - bestehend aus sog. Scan-Lines - zusammengefasst werden (Voodoo5).
Die beiden Methoden haben alle eines gemeinsam: Sie arbeiten niemals in oder auf dem selben Pixel.
Möglichkeiten der SLI-Zusammenarbeit
- SLI-Modus ohne RG-FSAA
In diesem Modus rendert jeder Chip parallel die "Scan-Line Bänder". Die mögliche Bandhöhe ist dabei frei programmierbar - zwischen 1 und 128 Scan-Lines (Für beide zusammengenommen natürlich) -. Damit ergibt sich dann zum Beispiel folgendes mögliche Szenario: VSA-100-Chip (#1) rendert die Scan-Lines 1 bis 32 und VSA-100-chip (#2) rendert im parallelen Zyklus dazu die Scan-Lines 33 bis 64 usw.
In diesem Modus rendert jeder VSA-100-chip 2 Pixel pro Takt, da jedoch beide parallel arbeiten wird insgesamt ein Output von 4 Pixel pro Takt erreicht. Jetzt wird hierbei natürlich - da wir uns ja nicht im RG-FSAA-Modus befinden - kein Subpixel oder Subsample gerendert sondern nur die Pixel an sich, sondern jeder VSA-100-Chip rendert 1 Subsample pro Pixel!
- SLI-Modus mit 2xRG-FSAA
Hier wird genauso wie im ersten Modus in parallelen "Scan-Line Bänder" gerendert.
Jedoch rendert zusätzlich jeder VSA-100-Chip noch 2 Subsamples pro Pixel (für das zweifache Anti-Aliasing halt). Da nun die doppelte Menge an Arbeit vorliegt, wird die Füllrate halbiert, so erreichen wir nur noch 2 Pixel pro Takt als Gesamtoutput.
Jeder VSA-100-Chip rendert 1 Pixel pro Takt, da 2 Subsamples gerendert werden. Weil jedoch beide VSA-100-Chips parallel laufen, ist die Gesamtfüllrate doppelt so hoch.
- SLI-Modus mit 4xRG-FSAA:
Auch hier rendert jeder VSA-100-Chip wieder jeweils 2 Subsamples pro Pixel.
Um nun 4 Subsamples pro Takt zu ermöglichen, werden beide Subsamples von beiden VSA-100-Chips kombiniert und ermöglichen so 4 Subsamples pro Takt.
Das besondere bei diesem Modus ist, dass wir nicht mehr im SLI sind, weil jeder VSA- 100-Chip auf dem selben Pixel arbeitet (!) - um die 4 Subsamples ja zu ermöglichen. Der Unterschied besteht jedoch weiterhin, wenn auch auf dem selben Pixel gearbeitet wird, so wird dennoch auf unterschiedlicher Subpixel-Ebene gearbeitet (sonst könnten ja auch nicht 4 unterschiedlich Subsamples möglich sein!).
So rendert jeder VSA-100-Chip wieder 2 Subsamples pro Pixel und beide VSA-100-Chips arbeiten wieder parallel, um die 4 Subsamples pro Takt zu erreichen. So erreichen wir in diesem RG-FSAA-Modus eine Single-Pixel-pro-Takt Füllrate, in Wahrheit wird somit jedoch ein 4-Subsample-Pixel-pro-Takt Füllrate erreicht). Dies entspricht jedoch nicht dem SLI!
- SLI-Modus ohne RG-FSAA
Dieser Modus arbeitet äquivalent zur Methode #1 beim Vorhandensein von nur 2 VSA-100. Die Arbeitsverteilung ist jedoch ein wenig anders (da ja 2 VSA-100 sonst "arbeitslos wären). Also wird zum Beispiel VSA-100-chip #1 Scan-Lines 1 bis 8, #2 9 bis 16, #3 16 bis 24, #4 25 bis 32, alle arbeiten natürlich wieder komplett parallel zueinander. Da jeder VSA-100-Chip eine 2 Pixel pro Takt Füllrate erreicht und sie parallel arbeiten, werden insgesamt 8 Pixel pro Takt Füllrate in diesem Modus erreicht.
- SLI-Modus mit 2xRG-FSAA
Dieser Modus ist identisch zur Methode #2 beim Vorhandensein von nur 2 VSA-100. Jedoch werden, weil ja 4 VSA-100-Chips vorhanden sind, insgesamt eine 4 Pixel pro Takt Füllrate erreicht.
- SLI-Modus mit 4xRG-FSAA
Dieser Modus unterscheidet sich etwas von den anderen Methoden. Zu allererst werden die 4 VSA-100-Chips in 2 gleiche Paare zu je 2 Chips aufgeteilt. Jedes dieser "Paare" rendert nun 4 Subsample-Pixel (wobei jeder VSA-100-Chip, von den zweien die zu einem "Paar" zusammengefasst wurden, wieder 2 Subsamples rendert und diese wieder miteinander kombiniert werden, um die 4 Subsample-Pixel zu erstellen), und ebenfalls werden hier wieder in Scan-Lines Pixel pro Takt für ein Subsample-Pixel benötigt und es zwei dieser "Paare" gibt, werden effektiv 2 Pixel pro Takt Füllrate erreicht. Die Arbeitsweise entspricht hier trotzdem dem bekannten Schema: Also ein "Chip-Paar" übernimmt die Scan-Lines 1 bis 32 und das andere "Paar" 33 bis 64, beispielsweise (wieder komplett parallel natürlich). Da jedes "Paar" nun 1 dem Begriff SLI (anders als in Methode #3 beim Vorhandensein von nur 2 VSA-100).
- SLI-Modus mit 8xRG-FSAA
Dieser Modus entspricht nun viel eher der Methode #3 beim Vorhandensein von nur 2 VSA-100. Die "Chip-Paare" rendern wieder 2 Subsamples pro Pixel (jeder Chip im Paar für sich) und kombiniert sie zusammen zu einem 4 Subsample-Pixel. Diese werden nun mit den 4 Subsample-Pixel vom anderen "Chip-Paar" kombiniert, so dass ein 8 Subsample- Pixel dabei entsteht. Da alle Chips wieder komplett parallel arbeiten erreichen wir pro VSA-100 wieder eine Single-Pixel-pro-Takt Füllrate, wobei effektiv jedoch eine 4 Pixel pro Takt Füllrate entsteht. Dies ist jedoch kein SLI, da ja auf dem selben Pixel gearbeitet wird (beim kombinieren der beiden 4 Subsample-Pixels), jedoch auf unterschiedlicher Subpixel-Ebene.
SLI arbeitet durch die Partitionierung des Bildschirms in "Scan-Line-Bändern" - es teilt den Bildschirm dabei nicht in Hälften auf (so wie die "SLI-Variante" von Metabyte) -. Durch den Einflusses des T-Buffers muss jeder VSA-100-Chip mit 2 Subsamples arbeiten: Also mit einer 2 Chip-Variante ergibt dies ein Total von 4 Subsamples, nur dies aktiviert die vollen T-Buffer-Funktionen und natürlich auch genauso die 4xRG-FSAA (es ist zwar auch möglich bei nur total 2 Subsamples die T-Buffer-Funktionen zu aktivieren, jedoch ist deren sichtbares Ergebnis dann sehr gering). Wenn wir nun bei der 2-Chip-Variante (Voodoo5 5500) im "T-Buffer-Modus" sind - also mit 4 Subsamples minimal arbeiten - so handelt es sich nicht mehr um SLI im eigentlichen Sinne (laut Methode #3 beim Vorhandensein von nur 2 VSA-100). Der Nutzer hat also die Wahl: Entweder SLI und damit eine hohe Gesamtperformance oder aber T-Buffer & 4xRG-FSAA und damit eine niedrigere Gesamtperformance aber dafür eine deutlich höher Bildqualität. Die 4-Chip-Variante (Voodoo5 6000), wie schon bereits oben kurz erwähnt, beherrscht den simultanen Einsatz von SLI und "T-Buffer-Modus".
Jedes "Chip-Paar" kreiert ja seinen eigenen 4 Subsample-T-Buffer und fügt dann, je nach dem zugewiesenen "Scan-Line-Band", die Subsamples zusammen (laut Methode #3 beim Vorhandensein von 4 VSA-100). Auch hier kann natürlich wieder zugunsten von Geschwindigkeit ein 4-faches SLI erzwungen (anstatt nur 2-faches). Auch die Methode #4 mit 8xRG-FSAA kann mit dem T-Buffer-Effekten genutzt werden. Hierzu gelten dann jedoch auch wieder die selben Bedingungen, wie für die 2-Chip-Variante (also kein SLI möglich).
Zum Chip
Auffällig ist, dass eine T-Buffernutzung mit nur einem VSA-100-Chip nicht möglich ist, es werden mindestens zwei VSA-100 benötigt, um den T-Buffer zu nutzen.
Hier kommt auch gleich die Besonderheit des VSA-100-Chips zum tragen, er ist nämlich MultiChipfähig, es können bis zu 32 VSA-100-Chips zusammenarbeiten (und sie tun es bei bestimmten Workstationkarten auch).
Auch ist ein Punkt sehr unklar: "AGP-Features, sind sie vorhanden oder nicht?".
Der VSA-100 unterstützt keine exekutiven AGP-Modi (also kein AGP-Texturing), da dies jedoch keine signifikanten Vorteile in Anwendung bringt, ist dem auch nicht nachzutrauern.
Es ist die Rede von bis zu 32 MB Hochgeschwindigkeit SDRAM pro VSA-100-Chip, warum kein DDR SDRAM? Zu der Zeit als der VSA-100 entworfen wurde war DDR SDRAM noch wesentlich teurer als SDRAM und so sah man keinen direkten Anlass ihn dahingegen auf DDR auch zu spezifizieren. Es sollte jedoch eine später Version (der VSA-101) auch mit DDR SDRAM zusammenarbeiten können. Das Interessante dabei ist natürlich die Speicherung der Texturen. So müssen gewisse Texturen doppelt vorhanden sein (jeder Chip verfügt ja bekanntlich über maximal 32 MB Grafikkartenspeicher, der determiniert ist, also nicht getauscht wird untereinander), es handelt sich dabei um die Texturen, die in den entsprechenden "Scan-Line-Band" liegen - also kann, je nach geschickter Wahl dieser "Textur-mehr-Aufwand" gesteuert/vermindert werden -. Der Frame-Buffer und der Subsample-Buffer ist dabei jeweils komprimiert vorliegend in jedem 32 MB-Paar des zugehörigen Chips, so wird kein unnötiger Platz verschwendet beim kreieren der Subsamples und einzelnen Frames.
Die Textur-Management-Units (TMUs) sind zweifach vorhanden, jede von ihnen verfügt über 2 Pipelines, beim verwenden von Single-Texturing pro Pixel-Modus, erreicht man hiermit eine vollwertige 2 Pixel pro Takt Füllrate. Wenn hingegen im Dual-Texturing pro Pixel-Modus wird nur noch eine effektive Füllrate von einem Single Pixel pro Takt erreicht. Dies bedeutet, dass die Single-Textur Füllrate für einen einzelnen VSA-100-Chip doppelt so hoch ist wie für der eine Voodoo3, auf der selben Frequenz getaktet, die Dual-Texturing Füllrate entspricht annähernd dem der Voodoo3 hierbei. Durch einige Änderungen in der Microarchitektur werden jedoch ca 20% mehr Leistung von dem VSA-100-Chip im Multi-Texturing geboten als im Vergleich zu einem gleichgetakteten Voodoo3-Chip.
Warum gibt es nun keine 3-Chip-Varianten bzw. kein 6xRG-FSAA?
Auch hier ist die Beantwortung wieder einmal simpel: Eine 3-Chip-Variante wurde von dem Hersteller (3dfx) ausgeschlossen, da ansonsten mathematische Probleme auftreten würden bei der Adressierung von Berechnungen unter bestimmten Umständen, so wäre eine neue Lösung zum Erstellen der 4 Subsamples benötigt worden, was dem Mehraufwand in der Entwicklung sicherlich nicht förderlich gewesen wäre. Der 6xRG-FSAA-Modus hat dabei ein ähnliches Problem mit den Subsamples, man hätte ein VSA-100-Model benötigt, welches mindestens 3 Pixel pro Takt berechnen kann (und nicht nur 2 wie im originalen VSA-100), also fiel dies weg für den VSA-100-Chip.
Methoden
Der VSA-100-Chip beherrscht definitiv 2xRG-FSAA und je nach Anzahl der Chips verdoppelt sich auch die Anzahl der Samples. Anti-Aliasing hat erst einmal im Prinzip etwas mit dem Rendering auf Subpixel-Ebene zu tun: Die Zahl 2x, 4x oder 8x bedeutet schlechthin, dass die 2-, 4- oder 8-fache Anzahl von Pixeln gerendert werden, jeweils die Hälfte davon auf horizontaler und die andere Hälfte auf vertikaler Subpixel-Achse (also 1:1, 2:2 oder 4:4).
Dadurch wird ein Pixel doppelt, vierfach bzw. achtfach so genau auf Subpixelebene abgetastet als dies normal geschehen würde. Das interessante dabei ist, dass die Subpixel um 45° gedreht werden, so werden aus 4 Subpixeln 8 Abtastungen, dies entspricht dann einer Genauigkeit von 8 Subsamples, obwohl eigentlich nur 4 verwendet wurden. Beim 8xRG-FSAA werden sogar stolzen 16 Abtastungen (also je 2 pro Subpixel) erreicht.
Ein VSA-100-Chip kann bis auf 2 Subsamples (Im folgenden zur Vereinfachung Modus-0 genannt) genau auf einen Pixel rendern. Die Füllrate sinkt dabei von der ursprünglichen 2 Pixel pro Takt Leistung (wenn kein RG-FSAA aktiviert ist) auf den 1 Pixel pro Takt Leistung im Modus-0. Aus einem Pixel werden folglich 2 Subpixel abgeleitet, diese werden um 45° gedreht. So wird einmal der X- und der Y-Wert abgetastet und durch das Drehen entsteht noch ein weiterer, versetzter X'- und Y'-Wert (mit ' bezeichnet, um den Unterschied zu verdeutlichen, es handelt sich nicht um den selben Wert!), der ebenfalls abgetastet wird. Die Subsamples werden dann im Framebuffer zusammengefügt und auf den Bildschirm ausgegeben. Der Modus-0 wird für alle anderen Anti-Aliasing-Methoden vorausgesetzt, so entsteht dann das 4xRG-FSAA oder gar das 8xRG-FSAA, je nach VSA-100-Anzahl (der genaue Arbeitsvorgang ist unter den verschiedenen SLI-Modi bereits weiter oben zusammengefasst).

rotated grid full scene Anti-Aliasing
Der T-Buffer wurde von 3dfx dafür konzipiert, um Spielen einen neuen Grad an Realismus zu geben, er stellt neben dem Anti-Aliasing und den Shadern die wichtigste Erneuerung in der Grafikkartenindustrie dar, es soll Photorealismus dargestellt werden.
Der Unterschied zwischen einer in Echtzeit gerenderten Szene und einer "vorberechneten" Szene ist auch heut noch deutlich sichtbar. Bisher wurde auf normalen Konsumer-PCs keine derartigen photorealistischen Effekte ermöglicht, der T-Buffer sollte dies ändern. Unterstützt werden dabei:
- Fullscene-Spatial-Anti-Aliasing (FSAA)
um die bereits angesprochene Kantenglättung zu ermöglichen, dem RG-FSAA - Motion Blur (MB)
um einen "Verwischeffekt" bei sich bewegenden Objekten zu erzielen: Einen Schweif beispielsweise - Depth of Field (DoF)
um einer Szene "Tiefenunschärfe" hinzuzufügen bzw. um bestimmte Objekte mit unterschiedlichen Schärfe-Einstellungen zu fokussieren - Soft Shadows and Soft Reflections
um weiche Schatten bzw. Reflexionen darzustellen
Das FSAA eliminiert "Bildungenauigkeiten", um es salopp auszudrücken, ganz spezifisch sind hier die auffallenden Schrägen von schiefen Objekten gemeint, die eine Art Treppe bilden, sie werden auch als "spatiale Artefakte" bezeichnet. Das Spatial-Anti-Aliasing "glättet" diese Artefakte nun und verhindert so den Treppeneffekt (wie genau dies abläuft steht bereits im Abschnitt: "Anti-Aliasing im Detail"). Aber es gibt noch ein weiteres Bildartefakte, neben dem "Treppeneffekt", dem sog. "funkeln" (engl. scintillating) oder "plötzliches auftreten" (engl. popping) von Polygonen. Mit "funkeln" ist hierbei schlicht das Problem gemeint, wenn ein dünnes, schmales Polygonobjekt in ferner Distanz anfängt zu flimmern, also die Polygone abwechselnd entweder dargestellt oder weggelassen werden, oftmals fehlt dann eine Verbindungslinie in der Bewegung oder ähnliches. Ursache hierfür ist eine zu geringe Auflösung des Samples (engl. under-sampling), wobei die Genauigkeit auf Sample-Ebene einfach nicht ausreichend ist eine - ja eigentlich unendliche - 3D-Umgebung darzustellen. Dies gehört ebenfalls in den Bereich der spatialen Artefakte. Eine weitere "Unterkategorie" des FSAA ist das temporäre Anti-Aliasing, dies wird genutzt, um MB zu erzielen und desweiteren noch das fokussierende Anti-Aliasing, um das DoF darzustellen. Beim Anti-Aliasing sollte man unbedingt zwischen dem Fullscene- und dem Edge-Anti-Aliasing unterscheiden, beim letzteren werden nämlich bloß die Außenkanten der Polygone geglättet und nicht das generelle Problem des "under-samplings", dem "scintillating", behoben und ergibt dann daher auch im Endeffekt eine niederwertige Bildqualität.
Das temporäre Aliasing, ist ein weiteres Manko in der Bildqualität, es sorgt für einen statischen Eindruck von Objekten, da alle Ecken die gleiche Tiefenschärfe aufweisen. Die Anomalie beruht jedoch nicht nur auf ein "under-sampling" sondern viel eher die Bewegung des Objektes ist die Ursache, da jene nicht mit einer genügend hohen Frequenz abgetastet und dargestellt wird und so die Sample-Rate zu gering ist. Als Ergebnis sieht man eine bildhafte (sprunghafte) Bewegung des Objektes von einem Frame zum nächsten, anstatt eine fließende (filmähnliche) Bewegung. Um diesem entgegenzuwirken erhöht man einfach die Anzahl der Bewegungsphasen des Objektes und bringt diese in die selbe Frame hinein, dies ist jedoch absolut unökonomisch und viel zu Leistungsintensiv für normale Grafikkarten. Im T-Buffer wird der selbe Effekt viel leistungsschonender erzielt, indem einfach mehrere getrennte Bewegungsdaten zusammengefasst werden. Also spielen wieder die Subsamples eine große Rolle, so können 2, 4 oder 8 dieser Subsamples zusammengefasst werden - anders als beim Anti-Aliasing ist hier jedoch nicht die mehrfache Abtastung in X oder Y-Richtung wichtig sondern viel eher die Gesamtanzahl der Samples im Verlauf der Bewegung. Dies äußert sich dann durch den MB bei den sich bewegenden Objekten als sichtbaren Effekt auf dem Bildschirm. Anstatt eine zusammengefasste Bewegung pro Frame zu sehen, entstehen mehrere Bewegungs-Samples zu einer Bewegung. Dies erklärt auch, warum der 2xT-Buffer eigentlich ungeeignet ist für MB, da so nur 2 Bewegungs-Samples sichtbar wären und dies für einen glaubwürdigen Effekt nicht ausreicht, sondern wenigstens 4 Bewegungs-Samples nötig sind, um auch optisch attraktiv zu sein. Das Ganze verleiht dem Bild dann mehr Realismus und nimmt die sonst übliche "Statik" der Computerszenen.

Motion Blur
Ähnlich verhält es sich mit dem DoF, er erzeugt Tiefenunschärfe und fokussiert bestimmte Objekte. Der Vorgang funktioniert ähnlich wie beim MB, die Subsamples spielen auch hier wieder die bedeutendste Rolle beim Kreieren des Effektes. Jedoch nicht wie beim Anti-Aliasing oder beim MB sondern viel mehr als Teilbilder für fokussierende Objekte. So wird beispielsweise eine Vase im Hintergrund fokussiert (scharf dargestellt) und die Umgebung als unscharf aufgefasst, dies wird dann in einem Bildausschnitt festgehalten (in sogenannten Fokus-Smaples) und immer so weiterberechnet - also nur den fokussierten Teilausschnitt als Weiterberechnung - anstatt das gesamte Bild weiter zu berechnen.

Depth of Field
Die Kombination von MB und DoF wird genutzt, um sanfte Schatten (auch Halbschatten) und Reflexionsunschärfe darzustellen. Bisher wird der Stencil-Buffer, verwendet um Schatten von Objekten zu kreieren, dabei entstehen unnatürlich scharfe Kanten beim Schattenumriss. Unter Verwendung des T-Buffers können Halbschatten dargestellt werden. Bei der Reflexionsunschärfe handelt es sich um ein Phänomen aus der Natur, wo zum Beispiel poliertes Holz nur matt reflektiert, welches abhängig von der Nähe des Betrachters zum Reflexionsobjekt war, dieser Effekt war bisher nicht realisierbar.

Soft Shadows und Soft Reflections
Allgemein kann man die verwendete Technik auch als Multi-Sampling bezeichnen. Die Arbeitsweise des T-Buffers ist bei all diesen Effekten wie folgt:
- Der Back-Buffer wird gelöscht
- es wird die gewünschte Anzahl der Bilder in den Back-Buffer gerendert (maximal 8 bei 4 VSA-100-Chips)
- es tauschen zu letzt dann der Front- mit dem Back-Buffer den Inhalt, so wird nun im Front-Buffer das fertige Bild gelagert, welches auf dem Monitor auch erscheint
Die Stufe mit dem rendern von multiplen Bildern, wird dabei sooft wiederholt, wie die verwendeten Anzahl der Subsamples vorgeben, also 2, 4 oder 8 mal. Im Gegensatz zum Akkumulation-Buffer wird keine Stufe benötigt, wo der Akkumulation-Buffer zurück zum Back-Buffer geschrieben wird und dies spart Zeit und Ressourcen. Ein weiterer Vorteil gegenüber dem Akkumulation-Buffer ist, dass man die Effekte MB und DoF nun partikular einsetzen kann und nicht auf das ganze Bild angewendet werden müssen, da ja mehrere Schreibvorgänge im Back-Buffer vorgenommen werden.
In jedem 3D-Spiel werden Texturen verwendet, womit die "nackten" Polygone beklebt werden, um ihnen eine Struktur zu verleihen. Die Größe dieser Texturen schwankt dabei stark, je nach gewünschtem Effekt und Detailgrad wird sie größer. Der VSA-100 unterstützt eine Texturgröße mit bis zu 2048x2048 Pixeln in 32-bit. Einen Einsatz von solch gigantischen Texturen ist jedoch nicht möglich ohne ein bandbreitenschonendes Texturkompressionsverfahren zu benutzen, da ansonsten die Texturen von dieser Größe bis zu 16 MB Speicher belegen würde und somit nicht mehr viel Platz für andere Texturen bzw. wichtigeren Geometriedaten sein würde. Eine Lösung ist hierbei das FXT1 von 3dfx, es handelt sich um eine neue Form des Kompressionsverfahren, welches die Größe der Textur vermindert, so dass effektiv mehr genutzt werden können. Es ergibt sich dabei folgendes Verhältnis von Texturgrößen und Farbtiefen:
| Texturgröße | 8-bit | 16-bit | 24-bit | 32-bit | 4-bit FXT1 |
| 64*64 | 6 kb | 9 kb | 13 kb | 16 kb | 2 kb |
| 128*128 | 18 kb | 33 kb | 49 kb | 64 kb | 8 kb |
| 256*256 | 66 kb | 129 kb | 193 kb | 256 kb | 32 kb |
| 512*512 | 258 kb | 513 kb | 769 kb | 1024 kb | 128 kb |
| 1024*1024 | 1026 kb | 2049 kb | 3073 kb | 4096 kb | 512 kb |
| 2048*2048 | 4098 kb | 8193 kb | 12289 kb | 16384 kb | 2048 kb |
Beim FXT1 handelt es sich um ein 4-bit Texturkompressionsverfahren, wobei 4-bit pro Texel komprimiert werden. Das Kompressionsverfahren wird auch als "Encoding" bezeichnet. Beim FXT1 wird das Bild in mehrere 4x4 und / oder 4x8 Texel-Blöcke zerlegt (je nachdem, welches Verhältnis günstiger ist), dabei kommen vier verschiedene Algorithmen zum tragen, die je nach Bedarf und auch visueller Qualität genutzt werden:
- CC_MIXED
Ein 4x4 Texel-Block wird mit 2-bits pro Texel für lichtundurchlässige Texturen verwendet, zusätzlich besitzt jeder Block noch zwei 16-bit Farben, die im RGB 565 Format gespeichert werden. Diese zwei RGB 565 Farbwerte und noch zwei zusätzliche Farbwerte, welche durch das Interpolieren der beiden RGB 565 Farbwerte entstehen, bilden die primären Farbwerte des Texel-Blockes und diese sind verbunden mit der 4 Nachschlagtabelle für Farben. Ein 2-bit Index wird benutzt, um anzugeben, welcher Farbwert in der 4-Nachschlagtabelle für jeden Texel des 4x4 Blockes genutzt wird. Transparente Texturen werden dabei so kreiert, dass einfach eine der vier Farben transparent dargestellt wird. (Entspricht der normalen S3TC-Qualität und Funktionsweise)
- CC_HI
Ein 4x8 Texel-Block wird mit 3-bits pro Texel für lichtundurchlässige und transparente Texturen verwendet, wobei jeder Block zwei 15-bit Farben im RGB 555 Format enthält. Diese zwei RGB 555 Farbwerte und noch fünf zusätzliche Farbwerte, welche durch das Interpolieren der beiden RGB 555 Farbwerte entstehen, bilden die primären Farbwerte des Texel-Blockes. Zusätzlich ist ein achter Farbwert (neben den sieben bereits erwähnten) als transparente Farbe zugeordnet. Ein 3-bit Index wird benutzt, um anzugeben, welcher Farbwert in der 8-Nachschlagtabelle für jeden Texel des 4x8 Blockes genutzt wird. (Entspricht der besten Kompression für spatiale Auflösungen)
- CC_CHROMA
Ein 4x8 Texel-Block wird mit 2-bits pro Texel für lichtundurchlässige Texturen verwendet, wobei jeder Block vier 15-bit Farbwerte im RGB 555 Format enthält. Alle vier Farben werden nun direkt benutzt ohne jegliche Interpolation durchzuführen, um eine 4-Nachschlagtabelle zu kreieren. Der 2-bit Index, der jedem Texel im block zugeordnet ist, um die vier Farbwerte den individuellen Texeln zuzuordnen. Dieses direkte Verfahren unterstützt keine Transparenz. (Entspricht der besten Kompression für komplexe ganzfarbige Flächen ohne Transparenz)
- CC_ALPHA
Ein 4x8 Texel-Block wird mit 2-bits pro Texel für lichtundurchlässige und transparente Texturen verwendet, wobei jeder Block drei 20-bit Farbwerte im 5555 Format enthält. Der erste und der zweite 20-bit Farbwert werden für die primären Farbwerte des linken Anteils des 4x8 Texel-Blockes genutzt (einem 4x4 Texel-Block), wohingegen der zweite und der dritte 20-bit Farbwert für den rechten Anteil des 4x8 Texel-Blockes verwendet werden. Es werden in jedem Farbblock dann zusätzlich noch zwei Farbwerte durch Interpolation erstellt zwischen den beiden primären Farbwerten (links + rechts). Ein 2-bit Index gibt wieder an, welcher Farbwert aus der Nachschlagtabelle auf den bestimmten Texel zutrifft. (Entspricht der besten Kompression für komplexe Alpha Transparenzen im 4-bit pro Texel System)
Durch die seperative Verwendung dieser vier stark unterschiedlichen Kompressionsalgorithmen wird für jedes Bild eine sehr niedrige Fehlerquote betreffs der Farbfehler erzielt.
Nach der Kompression erfolgt die Dekompression ("Decoding"), diese findet beim FXT1 während des Texturmapping-Prozesses statt und ist im VSA-100 implementiert. Ein 2-bit Feld wird in einem Block gespeichert und die Logik entscheidet, welcher Algorithmus vorliegt, um die beste Bildqualität zu erhalten. Je nach vorher verwendetem Algorithmus wird nun ein dekodierter 32-bit Texel, welcher von der TMU weitergenutzt wird, erstellt.
Dies ist der komplexeste Abschnitt in diesem Artikel, zum einen, da es sich um ein Feature handelt, welches von den regulären 3dfx-Treiber nicht angeboten wird und zum anderen, weil es sich allgemein auch um eine schwierige Materie handelt. Deshalb erst einmal allgemein etwas zum Anistropischen Filtering sagen, bevor auf die Details der Nutzung durch den T-Buffer eingegangen wird.
Ein gängiges Verfahren, um Textur-Aliasing zu vermeiden ist das Mipmapping, dabei wird sehr oft eine Unschärfe zumeist in einer bestimmten Richtung als Nebeneffekt geschaffen, um das Aliasing in der entgegen gesetzten Richtung zu vermeiden. Ein anisotropisches Texturing würde diese unerwünschte Unschärfe durch ein Filtern in verschiedenen Richtungen unter unterschiedlichen Winkeln unterbinden, jedoch auf Kosten der Geschwindigkeit.
Das Texturemapping ist ein szenenkomplexitäts-erhöhender Multiplikator, wobei ein komplexes Bild in ein simpelstrukturiertes Bild aufgeschrieben wird, um die Szene komplexer zu gestalten. Das Mipmapping beinhaltet dabei einen distanz- und winkelvariierenden isotropischen "low-pass" Filter, wobei man davon ausgehen kann, dass die MIP-Filter-Größe von dem Winkel und der Distanz der betrachteten Textur abhängig ist, dennoch aber gleichmäßig über alle Richtungen der Textur geht (also in X- und Y-Richtung). Das korrekte Rendern von gestreckten Texturen oder betrachteten Texturen unter einen Winkel erfordert ein anisotropisches Filtern.

Ein Flughafen mit Landebahn in folgender Qualitätsreihenfolge: normales Mipmapping; 2 tap; 4 tap; 8 tap anisotropisches Filtering
Ein MIP-map besteht dabei aus einer pyramidialen vorgefilterten und "downgesampelten" (verkleinerten) Texturen, wobei jeder MIP-map-level dabei der um die Hälfte verkürzten Größe (in beiden Richtungen) des vorigen MIP-map-levels entspricht. Die TMU bestimmt nun einen Skalierungsfaktor der einzelnen Fragmente und wählt das nächst passende aus, also die zwei Mip-map-level, welche sich um den passenden Faktor unterscheiden. Die Hardware benutzt nun 1, 2, 4 oder 8 der acht umgebenden Texels, um den Farbwert des Fragmentes zu rekonstruieren. Während das Mipmapping einwandfrei auf Texturen anwendbar ist auf die direkt gesehen wird, so versagt diese Methode bei abweichenden Winkeln indem eine Unschärfe in eine Richtung produziert wird, um den Detailgrad in der anderen Richtung zu wahren. Die beste Methode ist es einen elliptischen Gauss'schen Filter zu benutzen, wobei eine Ellipse die Projektion eines zirkularen Gauss'schen Pixels mit dem sichtbaren Platz (Bildschirmplatz) und dem Texturplatz annähernd filtert. Es gibt zwei Möglichkeiten den elliptischen Filter zu konstruieren, zum einem mit rohen Texeln oder mit dem Kombinieren von unterschiedlichen MIP-map-samples mit dem Filterfußabdruck (daher auch der Name: "footprint assembly" => FA). Wobei die FA-basierenden Algorithmen mit relativ wenig MIP-map-samples auskommen und so ressourcenschonend arbeiten.
Das FA hat als Grundlage einen zirkularen Gaussfilter-Kernel, der ein Bildschirmfragment abdeckt. Wenn eine Oberfläche unter einem bestimmten Winkel eingesehen wird, so wird die Projektion dieses Kernels auf den Texturplatz angenähert durch einen elliptischen Gaussfilter durch die Summe von Texture-Samples.
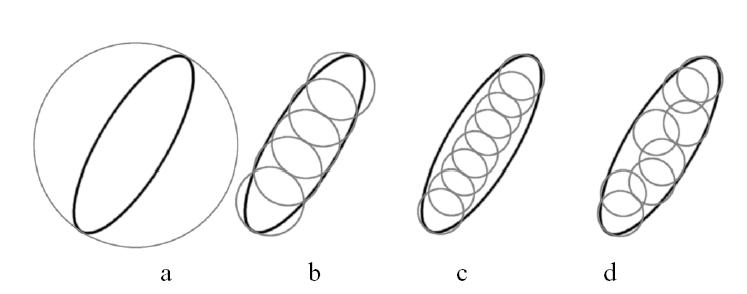
Zusammenstellen von elliptischen FA [schwarz] aus einem isotropischen MIP Textur-Samples [grau]. Die grauen Areale außerhalb des schwarzen Gebietes (FA) zeigen die Ort der späteren Unschärfe an. Die schwarzen Gebiete außerhalb der grauen Areal zeigen dahingegen ein späteres Textur-Anti-Aliasing an. a: normales MIP-mapping; b: normales FA mit den Texure-Samples; c: under-sampling wenn die Textur-Samples-Größe zu gering ist; d: Kompensierung mit außerhalb der Hauptachse liegenden Textur-Samples
In 2a sieht man den zirkularen Umriss, der symbolisiert, wie das Standard MIP arbeitet, durch zu große Samples außerhalb des "Fußabdruckes" (der Ellipse) würde dies zur Unschärfe der Textur führen. In 2b sieht man den idealen Verlauf durch die Textur-Samples als konzentrische Kreise. Der Hauptunterschied zwischen den einzelnen FA-Methoden besteht in der Anordnung und Platzierung der Textur-Samples. In der vollen Hardwareanpassung wird natürlich versucht so dicht wie möglich an der eigentlichen Ellipsenform zu bleiben (siehe in 2d). Das vertexbasierende anisotropische Texturing berechnet die Textur-Samples durch Vertexe (Scheitelpunkte), die Textur-Sample-Größe ist durch die Stufe des MIP-map-levels bestimmt.

Darstellung eines Ausschnittes beim FA entlang eines Dreieckes im Texturraum [Ausschnitt nicht größenreal]. a: normales MIP Texturing; b: schräg-zentrale Textur-Sample; c: vermischt mit einer in einer Richtung geänderte Textur-Sample; d: vermischt mit einer in zwei Richtungen geänderten Textur-Sample
Eine normal gezeichnete Textur gibt ein großes MIP Textur-Samples, zentriert auf jedem Fragment über die Geometrie (siehe 3a). Die Stufe des MIP-levels skaliert die Größe des Textur-Samples mit der Größe des Standard Mipmapping, welches ausgewählt wurde. Mit der Stufe des MIP bekommen wir kleinere Textur-Samples pro Fragment (siehe 3b), um nun ein Textur-Sample zu platzieren innerhalb des Texturareals - umgeben von den Fragmenten -, wird die Texturkoordinate jedes Vertexes um einen kleinen Betrag in die benötigte Richtung geändert (siehe 3c und 3d). Die Textur-Samples sind mit dem vermischen ("blending") von purer Vertexberechnung oder "per-pass Alpha" belastet, nur die Vertexberechnung wird hierbei im weiteren beachtet, diese birgt nun wieder 2 neue Fehlerquellen in sich:
- Zum einen kann ein einziges Polygon nun mehrere mögliche Texturskalierung aufweisen und somit unterschiedliche Stufen der Anisotropie hervorrufen. So ist es möglich ein Polygon mit einem 2:1 Anisotropie-Verhältnis am nahen Vertex zu haben oder einem 8:1 Anisotropie-Verhältnis am fernen Vertex.
- Zum anderen ändert sich wohlmöglich die Richtung der Anisotropie.
Weil die Stufen der Anisotropie auf dem Polygon variieren können ist man auf eine einzige mögliche Anzahl der Textur-Samples und eine Stufe des MIP-levels beschränkt. Um nun auch dem Ausnahmezustand (aus Abbildung 2a) gerecht zu werden, wurde die Anzahl der Textur-Samples und Stufen der MIP-levels auf Objekt-Ebene und nicht auf Polygon-Ebene angewendet.
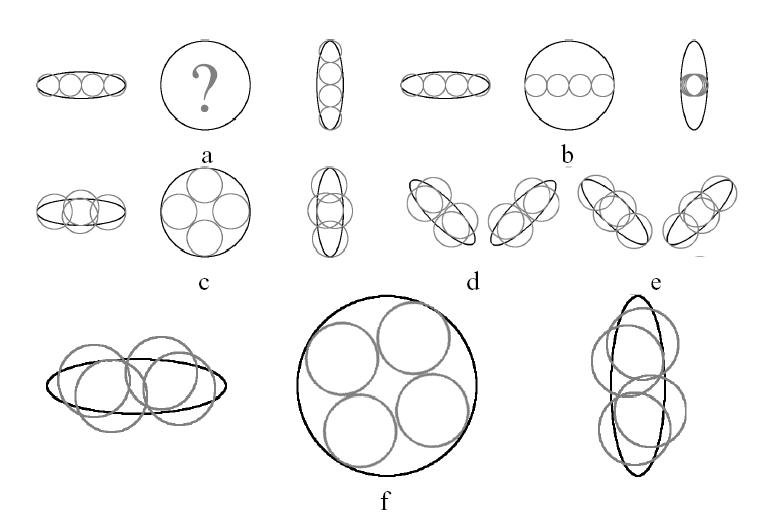
Abtastung von Textur-Samples für das Erstellen des elliptischen FA [schwarz] aus dem MIP Textur-Samples [grau]. a: entlang der Hauptachse der Ellipse, sich schlecht verhaltend wegen des Wechsels der Anisotropie; b: Vermeiden vom Abweichen von der Achse, mit starkem Aliasing; c: Abtastung mit völligem ausgefüllten Fußabdruck; d: Beispiel c dargestellt als Ellipse mit rotierter Ordinate; e: Beispiel c mit rotiert, um nach Anisotropie ausgerichtet zu sein; f: finales Textur-Sample
Wenn der Wechsel der Anisotropie auf einem Polygon nicht einheitlich geschieht bekommt man Aussetzer ("Offsets") in der Mitte des Polygons (siehe 4a und 4b). Die Höhe der Textur-Samples und der Textur-Aussetzer muss pro Durchlauf äquivalent auf dem Polygon sein. Um nun beide Fehler der Vertexberechnung zu eliminieren wird eine abweichende Sampling-Startegie genutzt: Der gesamte Fußabdruck wird abgetastet anstatt nur die platzierten Textur-Samples entlang der Hauptrichtung der Anisotropie (siehe 4c bis 4f). Dies erlaubt nun eine adäquate Rekonstruktion mit einer hohen Variabilität der zirkularem bis zu hoch exzentrischen Filterschärfe mit stets der selben Anzahl an Textur-Samples und Koordinaten. Um die Textur-Samples nun zusammenzufügen wird eine Transformation aus dem zirkularem Gauss'schen Filter und dem elliptischen Filter gemacht, die Position des Textur-Samples wird also von zirkularer zur elliptischen Ebene transformiert, um ein adäquates Überlappen der Samples zu garantieren, wird die Distanz der MIP-Stufen zueinander in Betracht gezogen (nur die angrenzenden Stufen). Dies lässt einen Freiheitsgrad im Algorithmus zu, der sich folgendermaßen äußert: Die Textur-Sample kann entweder vom kanonischen zirkularem Gebiet oder vom zirkularem zum elliptischen Gebiet transformiert werden.
Eine Möglichkeit der Transformation entlang der Hauptachse der Ellipse mit der X-Achse (Abszisse) im zirkularem Gebiet und von der Nebenachse (siehe 4a) mit der Y-Achse (Ordinate). Diese Möglichkeit ist gleich mit der Achsenberechnung des klassischen FA (im Gegensatz zum vertexbasiertem FA) aber ist ungeeignet für das nah-zirkulare vertexbasierte FA, die Auswahl, welche Achse länger ist ändert sich rapide und nicht vorhersehbar. Die Transformation vom Bildschirm zur Textur mit dem elliptischen Filter liefert ein stabileres Koordinatensystem (siehe 4c) aber es erfordert eine engere Abtastung, um Richtungsartefakte zu vermeiden (siehe 4d). Das System die Bildschirmkoordinaten zu erstellen ist dabei dasselbe, um auch Supersampling in Software darzustellen. So können wir nun ein stabileres Koordinatensystem erstellen, welches auch die Richtungen der Anisotropie erkennt, ohne dabei von der Haupt- und Nebenachse zu unterscheiden. Unsere finale Selektion für die Abtastung des Musters nutzt eine schwankende Anordnung (siehe 4f), dies vermeidet eine Verdoppelung, welches im Zentrum der entlanggegangen Achse auftritt. Es wird außerdem ein angenähertes Koordinatensystem, welches leichter für die Berechnungen ist und auch die Interpolationen unter den Polygonen berücksichtigt.

Auswirkungen auf das Abtastmuster und auf die MIP-map-Stufen. a: normales MIP-mapping mit Unschärfe im Hintergrund und in den vorderen Ecken; b: mit korrekter Größe angepasst entlang der Anisotropierichtung; c: gleich große Textur-Samples (nun jedoch zu klein), um das Muster zu zeigen; d: größere Textur-Samples entlang der Anisotropierichtung; e: große (jedoch korrekte) Text-Subsamples, um das Muster zu zeigen
Nun zum Realisieren auf VSA-100-Chips. Im Prinzip ist alles sehr einfach, man adressiert nur die 3dfx_multisample anstatt wie bisher die GL_EXT_texture_lod_bias oder die GL_SGIX_texture_lod_bias OpenGL-Extensionen. Das interessante dabei ist, dass die selben Subsamples wie für das RG-FSAA genutzt werden auch für diesen spezifischen Prozess verwendet werden können, also bis zu 16-faches Anisotropisches Filtering kombiniert mit 2xRG-FSAA ohne jeglichen Geschwindigkeitsverlust. Dabei werden 8 Textur-Samples genutzt und diese sind 2 mal abgetastet (für das FSAA) durch den "Jitter-Prozess", wobei die Subsamples-Anzahl der Jitter-Samples-Anzahl entspricht (also 8x2) und ohne merklichen Verlust an Leistung in diesem Modus. Für das 4xRG-FSAA ergibt sich dann 8x4, weil 4 Subsamples "gejittert" werden und ein effektives anisotropisches Filtering von 32 tap - auch hier ebenfalls ohne Leistungsverlust. Sobald der T-Buffer also genutzt werden kann steht auch automatisch die anisotropische Filterung zur Verfügung (als gl_anisotropic).